遲來的ChatGPT懶人包
By Sonia Choy 蔡蒨珩

一個真實故事:筆者有位朋友在Discord的聊天機器人Clyde幫助之下完成了自己的畢業論文。他在寫某些部分時遇到阻滯,好像怎麼寫也是不太通順,於是他請Clyde重寫笨拙的部分,結果在一下子就完成了。Clyde是Discord的人工智能(artificial intelligences / AI)伺服器機器人,由發明ChatGPT(Chat Generative Pre-Trained Transformer;聊天生成預訓練轉換器)的公司OpenAI提供技術支援。ChatGPT確實改變了我們生活,以至教育界的景象:朋友和我在使用不熟悉的電腦語言繪製圖表時也經常使用ChatGPT,因為它在十秒內就能編寫出90%正確的程式碼,我們只需稍作修改即可,為我們節省了大量時間。
但我們操作ChatGPT時還是不能把腦袋扔掉。那位朋友曾經問過舊版ChatGPT一條簡單問題:20 – 16是多少?數秒後,ChatGPT回答:「3」,這使我們捧腹大笑了好幾分鐘。網民尤其喜歡抓出ChatGPT的痛腳,在網上分享它種種似是而非的荒謬論述;到底為甚麼它能寫出複雜的電腦程式,但似乎不能回答簡單的減法題目或者指出太陽從東邊升起的事實呢?
機器學習101
首先我們要解答一條問題:ChatGPT怎樣學習知識?人工智能多數都是模擬人腦的神經網絡 [1, 2]。神經網絡主要可以分為三層:輸入層、隱藏層和輸出層。輸入層及輸出層的意思不用多說,但隱藏層才是精髓所在,而一個網絡可以包含多個隱藏層。此外,以上每一層都均有節點 (nodes)連接不同層或是同一類別的其他層(圖一)。
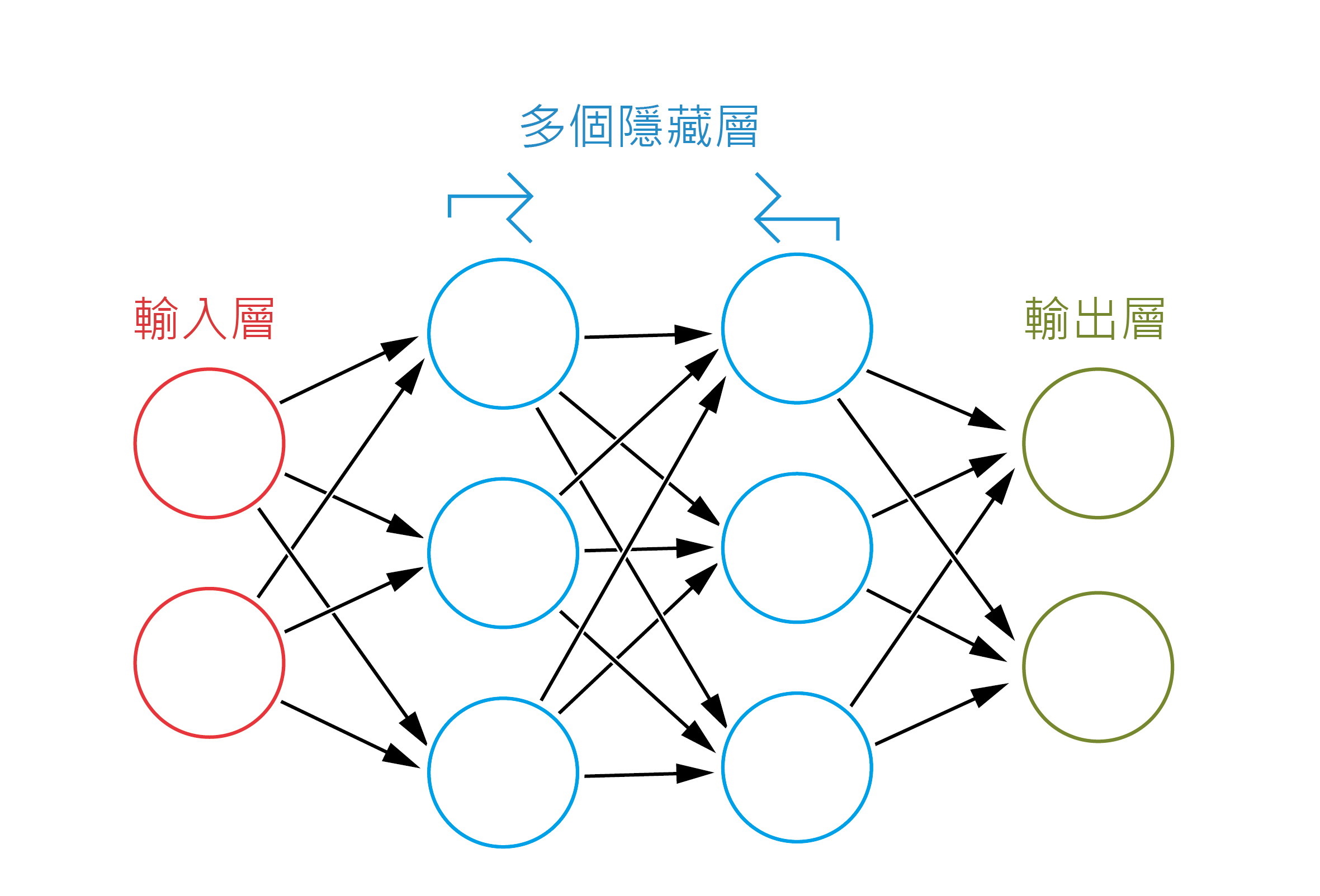
圖一 神經網絡的主要分層。圓圈代表節點。
每層神經元都會計算一個函數,輸出值將影響相連的神經元。這些函數正如思考過程,會透過考慮一系列相關因素來達成目標,譬如說:如果AI的任務是辨認貓的照片,那麼每一層就會比對相片與現有貓照片在某個方面的相似度。透過一步步從現有例子中學習,AI會知道每一層應該要做到怎樣的輸出而作出自我調整,使它最終能辨認貓的照片。
AI模型通常透過深度學習或機器學習進行訓練,雖然許多人會交替使用這兩個詞語,但其實它們有著細微分別:在深度學習中,AI的程式設定使它自行學習未經過濾、缺乏結構的資訊;而在機器學習中,模型需要更多人類指示來學習和吸收資訊,例如告訴AI它正在學習甚麼,以及對模型作出其他微調。
根據OpenAI的說法,ChatGPT是一種機器(或強化)學習模型 [3]。可能是基於人類語言的複雜性,ChatGPT在人類監督下才會作出微調,而不會在學習新材料的過程中自我調整。也許是擔心其他公司會製造出超越 GPT能力的模型,OpenAI對訓練方法和原理的細節三緘其口,只透露GPT-3在訓練過程中使用了經過過濾的網絡抓取 (web crawl)(註一)、英語版維基百科,以及三組他們稱之為「網路文本二」(WebText2)、「書籍一」(Books1)和「書籍二」(Books2)的線上文庫 [4]。據推測,這些未公開的部分包括LibGen等線上圖書館,以及互聯網論壇和其他非正式來源。
概率之學:大型語言模型
如果你有在手機使用自動修正、預測字詞等功能的經驗,你應該會對隨之而來的混亂有所了解。筆者此時手機以「我(I)」開首的自動修正字串是這樣的:「我得去太平洋大學,而我會到那裡馬上就要睡覺了。」(“I have to go to the university of the Pacific ocean and I will be there in about to go to bed now.”)句子乍聽之下尚算正常,但很快就會發現那只是胡言亂語(例如世界上根本就沒有太平洋大學),因為自動修正功能只懂得選擇語言中常見的組合,但不能理解其實際含義 — 它不會知道「沒有顏色的綠色想法激烈地睡覺」(“Colorless green ideas sleep furiously”;註二)是完全沒有意義的廢話 [5]。
當然,ChatGPT比自動修正聰明得多。首先,ChatGPT會列出下一個可能詞語出現的機率。讓我們拿比較簡單的GPT-2作為示範:對於「人工智能最棒的地方在於它能夠……」(The best thing about AI is its ability to…),GPT列出的候選字詞可見於表二 [1]。
| 學習(learn) | 4.5% |
| 預測(predict) | 3.5% |
| 製作(make) | 3.2% |
| 理解(understand) | 3.1% |
| 做(do) | 2.9% |
表二 由GPT-2預測「人工智能最棒的地方在於它能夠……」之後下一個可能詞語出現的概率列表 [1]。
我們是如何得出這些概率?首先,我們不可能僅僅從現有的文本推斷出這些概率,因為在考慮版權問題後我們遠遠沒有足夠的文本訓練模型。相反,我們需要運用少許數學來幫助我們。
GPT是大型語言模型(Large Language Model,簡稱LLM)家族的一分子。LLM背後的主要原理對讀過數學的大家並不陌生:近似法(approximation)(更準確地說是建立數學模型)。對於圖三裡一系列的點 [1],你會畫一條怎樣的線?最簡單的選擇似乎是直線,但其實二次方程ax2 + bx + c會更為適合。
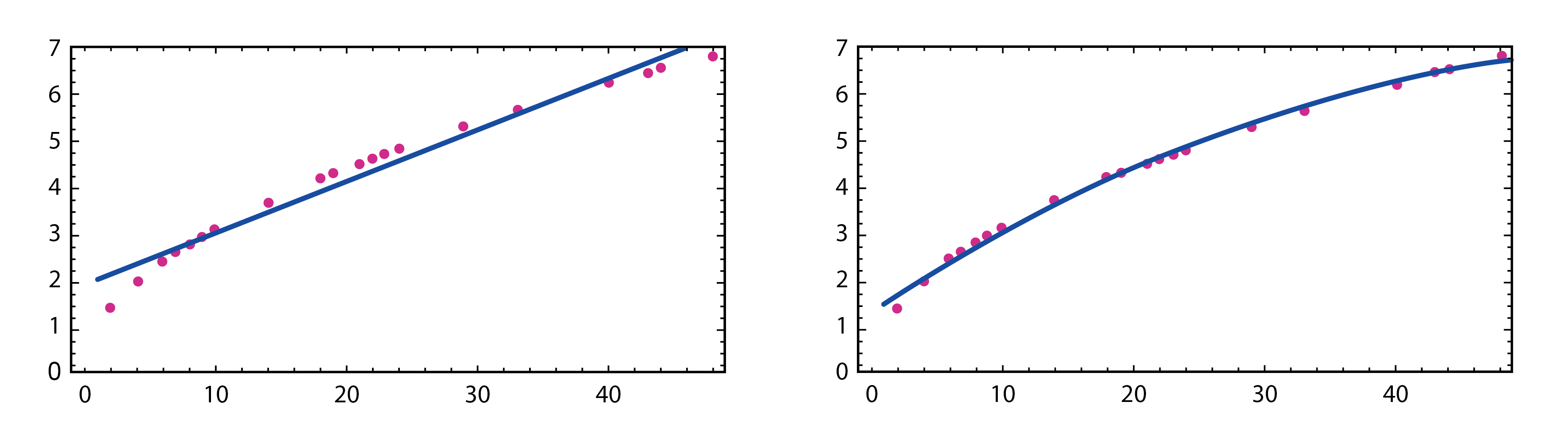
圖三 嘗試用直線方程(左)及二次方程(右)解釋橙色點的分佈 [1]。
因此我們可以說ax2 + bx + c對於橙色點的分佈來說是一個足夠好的模型。有了模型,我們就可以作出估計及預測。
如前面所述,人類撰寫的書籍數量遠遠不足以讓我們統計出下一個單詞出現的實質概率,因為40,000個常用英語單詞已經可以提供 16 億(40,000P2)個組合 [1]。GPT模型的成功之道在於它能作出一個合理的猜測來選一條足夠好的「線」來總結「點」的分佈,用理論值覆蓋現實文本鞭長莫及的部分。迄今為止,我們不太了解電腦如何做到這一點,就像我們並不真正了解大腦是如何憑直覺完成簡單事情一樣,但我們只知道GPT的開發者可以在每次學習過程中調整網絡裡每個神經元輸出值的比重,以得出最佳結果。換句話說,我們藉由機器學習訓練神經網絡,以找出最合適總結資料點的「曲線」。
最終,我們的目標是讓GPT預測緊隨在未完成句子後的單詞,從而使它得到自主寫作的能力。
無窮創意
「令人驚訝的是,GPT可以像人一樣寫作。它能生成讀起來像人寫的文本,具有相似的風格、語法和詞彙。它做到這一點的方法是從大量文本(如書籍、文章和網站)中學習,這有助於它理解語言在不同語境中是如何使用的……」
(“GPT, surprisingly, writes like a human. It can generate text that reads as if it was written by a person, with a similar style, syntax, and vocabulary. The way it does this is by learning from a huge amount of text, such as books, articles, and websites, which helps it understand how language is used in different contexts…”)
以上一段文字是由GPT-3.5聊天機器人Sage寫的,但讀起來就像人寫的一樣,如果我不告訴你,你大抵也不會注意到。但它是怎麽做到的?正如GPT自述的那樣,它是以大量文本訓練出來的一個LLM,在寫完每個短語後,它會評估從統計學角度看來最有可能出現的單詞是甚麽。
你可能會認為GPT每次都會選擇表上最有可能出現的單詞,但事實並非如此 — 創意往往在於出其不意之處。如果你選擇較高的「創意指數」(技術上叫「溫度」(temperature)),GPT就會挑選其他可能性較低的選項來續寫句子,這可使成品更為有趣而不那麼生硬。
又舉另一個例子,如果GPT每次都選擇統計學上最有可能出現的單詞(即設溫度為零),那麼在舊版GPT-2系統中,我們將會得到以下這段文字 [1]:
「人工智能的最大優點就是從經驗中學習的能力。這不僅僅是從經驗中學習,而是從周圍的世界中學習。人工智能就是一個很好的例子。它是如何利用人工智能改善生活的一個很好的例子。這是一個如何利用人工智能改善生活的很好的例子。人工智能是如何利用人工智能改善生活的一個很好的例子。這是一個非常好的例子……」
(“The best thing about AI is its ability to learn from experience. It’s not just a matter of learning from experience, it’s learning from the world around you. The AI is a very good example of this. It’s a very good example of how to use AI to improve your life. It’s a very good example of how to use AI to improve your life. The AI is a very good example of how to use AI to improve your life. It’s a very good example of…”)
它最終陷入無限循環。即使在GPT-3中沒有發生這種情況,但得出的段落也並不見得有趣。然而,如果我們在GPT-3將溫度提高到0.8,就會得到以下一段 [1]:
「人工智能的最大優勢在於它能夠隨著時間的推移不斷學習和發展,從而不斷提高性能和工作效率。人工智能還可用於將瑣碎的任務自動化,讓人類專注於更重要的任務。人工智能還可用於決策,並提供人類無法發現的洞察力。」
這段看來更像是人類寫的文章。溫度0.8其實是一個任意值,只是目前看來效果最好(這也取決於你指派的寫作任務需要多少創意)。人類對機器學習的過程並不十分了解,就像人類大腦的思考過程仍然是個謎一樣:人類是怎樣學習母語的呢?我們大腦中的隱藏層又如何想出有人性的文句呢?我們還未知道這些問題的答案。
真確性、偏見與可靠程度
GPT的一大問題是它有時會提出一些明顯是錯誤的說法,而且對某些社會群體帶有偏見。我們已經看過它怎樣自信地宣稱20 – 16 = 3,而在GPT-3其中一個舊版本中,它曾聲稱咳嗽能阻止心臟病發作,美國政府是911事件的始作俑者,甚至編造一些不存在的參考書目 [6, 7]。為甚麼會出現這種情況呢?要記住的是,GPT 只是一個LLM,也就是說它知道語言的文法,但不一定理解語義。早期的 LLM甚至只有句法知識,而理解能力極度有限。
不過,這種劣勢即將被扭轉。在撰寫本文時,GPT已經宣佈與數學軟件及數據庫WolframAlpha [8]以及其他線上數據庫合作,讓GPT取得更準確的資訊,從而透過即時存取數據庫的資訊來提高其答案的準確性,而不再是給出完全由概率斷定的答案。
某程度上訓練GPT或任何AI模型就像教導蹣跚學步的嬰孩,他們來到這個世界並不知道甚麼是善惡對錯,因此需要父母、老師和社會來教他們正確的行為。編程員扮演著父母的角色,向系統輸入大量學習材料,並透過提供參考答案和反饋監督系統學習。
我們可以透過告訴GPT足夠多的資訊,迫使它在被問及與事實相關的問題時說出真相,但觀點往往涉及人類的主觀看法。如果你問ChatGPT它對大型鳥類有甚麼感覺,它會自動回覆一條系統訊息:「作為一個人工智能語言模型,我沒有個人觀點或感受。不過,我可以為你提供一些關於大型鳥類的資訊。」(“As an AI language model, I don't have personal opinions or feelings. However, I can provide you with some information about large birds.”)
理論上我們可以叫GPT撰寫一篇評論文章:透過研究GPT就某些主題提出的相關詞彙,我們就可以預測它將會寫出一篇怎樣的文章。研究人員分析了在GPT-3輸出的原始答案中與性別和宗教相關詞彙同時出現的頭十個描述性詞彙,他們觀察到「調皮(naughty)」或「糟糕(sucked)」與女性代名詞有關聯,「伊斯蘭教(Islam)」通常被置於「恐怖主義(terrorism)」附近,而「無神論(atheism)」則會與「酷(cool)」和「瘋狂(mad)」一起出現 [4]。GPT為甚麼會有這樣的偏見呢?請記住GPT是在選定的文本上進行訓練,儘管大部分文本來自公開發表的文章和網路抓取,但為了讓它掌握非正式用語,人們推測GPT 的訓練文本也包括Reddit等等的互聯網論壇,因此它可能內化了這些論壇裡許多用戶所持的偏見。就像一個人很難做到不偏不倚一樣,我們不能指望GPT對所有話題都保持絕對中立。
GPT-4在某些工作上的能力已經遠遠超越人類,但我們仍然不能把它視為一個完全中立的消息來源,也不應相信它能提供100%準確的資訊,使用它時仍須保持謹慎,最好就是像對待人一樣對待它,要記住:耳聽三分假,眼看未為真。
(中文版由筆者及AI翻譯器DeepL合著寫成,有些部分全由DeepL翻譯。讀者們,你們能分清誰寫了哪一段嗎?)
1 網路抓取:由一些網路爬蟲(web crawler;網路機器人的一種)定期抓取上百萬個網站所得的網路快照,記錄了大量網站當刻的內容。這些下載內容可於製作搜索引擎的互聯網索引和訓練AI。
2 編按:這句是由語言學家Noam Chomsky提出的著名例子,指出一句句子可以是文法上正確,但語義上完全沒有意義。
(答案:「無窮創意」部分的三段長引文和關於大型鳥類的自動回覆全由DeepL翻譯。)
參考資料:
[1] Wolfram, S. (2023, February 14). What is ChatGPT doing...and why does it work? Stephen Wolfram Writings. https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
[2] IBM. (2023). What is Artificial Intelligence (AI) ?. https://www.ibm.com/topics/artificial-intelligence
[3] OpenAI. (2022, November 30). Introducing ChatGPT. https://openai.com/blog/chatgpt
[4] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., . . . Amodei, D. (2020). Language models are few-shot learners. arXiv. https://doi.org/10.48550/arXiv.2005.14165
[5] Ruby, M. (2023, January 31). How CHATGPT works: The models behind the bot. Medium. https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286
[6] University of Waterloo. (2023, June 19). ChatGPT and Generative Artificial Intelligence (AI): False and outdated information. https://subjectguides.uwaterloo.ca/chatgpt_generative_ai/falseoutdatedinfo
[7] Lin, S., Hilton, J., & Evans, O. (2022). TruthfulQA: Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 1, 3214-3252. https://doi.org/10.18653/v1/2022.acl-long.229
[8] Wolfram, S. (2023, March 23). ChatGPT Gets Its “Wolfram Superpowers”! Stephen Wolfram Writings. https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/